PCA and Clustering Analysis Project
Project Overview
This comprehensive Jupyter Notebook presents an in-depth statistical analysis of the Netflix Dataset, leveraging advanced data science techniques to uncover meaningful patterns and insights within the streaming platform's content library.
The project focuses on exploring content trends, distribution patterns, and key characteristics including genres, languages, and IMDb ratings over time. By applying Principal Component Analysis (PCA) and various clustering algorithms, we gain a deeper understanding of the factors that influence content popularity and viewer ratings on Netflix.
Methodology
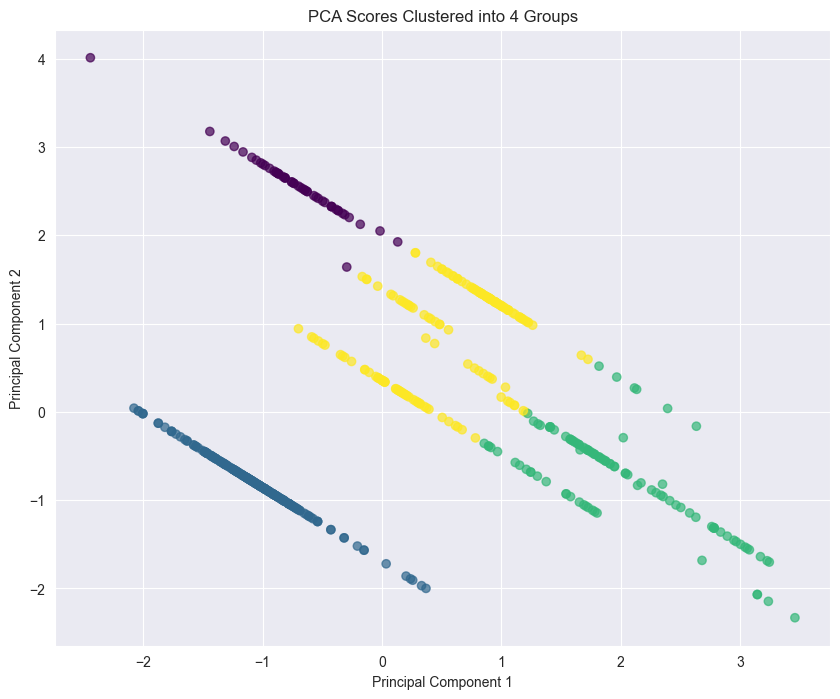
Principal Component Analysis
Dimensionality reduction technique used to identify the most significant features and patterns in the Netflix content dataset, revealing underlying structures in viewer preferences and content characteristics.
Clustering Analysis
Unsupervised learning techniques applied to group similar content together based on multiple features, enabling the discovery of natural content categories and audience segments.
Trend Analysis
Temporal analysis of content characteristics over time to identify shifts in content strategy, genre popularity, and rating patterns across Netflix's content library evolution.
Rating Correlation
Statistical correlation analysis between various content attributes and IMDb ratings to understand which factors most significantly impact viewer satisfaction and content success.
Key Research Questions
- ? What are the dominant content trends and patterns within the Netflix catalog?
- ? How do different content characteristics correlate with viewer ratings and popularity?
- ? Can we identify distinct content clusters that represent different audience segments?
- ? How have content characteristics and ratings evolved over time on the platform?
- ? Which factors have the strongest predictive power for content success?
Technical Stack
Python
Jupyter Notebook
Pandas
Scikit-learn
Matplotlib
Seaborn
NumPy
SciPy
Real-World Applications
Content Recommendation Systems
Insights from clustering analysis can inform personalized recommendation algorithms by identifying content similarities beyond simple genre classifications.
Content Acquisition Strategy
Understanding patterns in highly-rated content helps guide decisions about which types of shows and movies to acquire or produce.
Marketing and Promotion
Identifying distinct audience segments through clustering enables more targeted marketing campaigns and content promotion strategies.
View Full Analysis
Explore the complete Jupyter notebook with detailed visualizations, code, and findings.