Mandelbrot GPU Computation with CUDA
Overview
This project demonstrates a GPU-accelerated computation of the Mandelbrot set using CUDA and Julia. The implementation leverages GPU parallelism to efficiently compute the fractal, optimizing memory access patterns and maximizing computational throughput. The result is a high-resolution image of the Mandelbrot set, visualized with a red intensity gradient, highlighting divergence patterns as they approach the maximum iteration count.
Performance Metrics
We measure GPU performance using three key metrics:
- • Execution Time: Time taken to compute the Mandelbrot set on the GPU.
- • FLOPS (Floating-Point Operations Per Second): Measures the computational efficiency of the GPU kernel.
- • Bandwidth: Indicates the memory transfer rate between the CPU and GPU.
GPU Performance Comparison
| GPU Model | Execution Time (ms) | FLOPS (GFLOPS) | Bandwidth (GB/s) |
|---|---|---|---|
| RTX 4080 | 23.04 | 119,315.91 | 34.96 |
| A100 | 64.81 | 42,414.90 | 12.43 |
Key Observations:
- ✓ The RTX 4080 outperforms the A100 in both FLOPS and memory bandwidth.
- ✓ The RTX 4080 achieves 2.81× higher FLOPS than the A100, indicating better computational efficiency for this workload.
- ✓ The RTX 4080's bandwidth is nearly 3× higher than the A100, making it more suitable for memory-intensive operations.
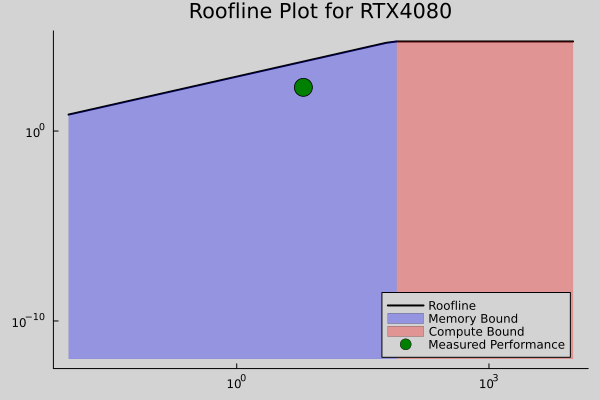
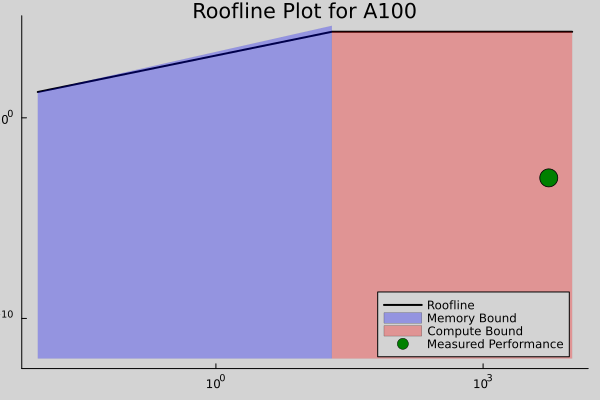
Roofline Plot Analysis
The following roofline plots illustrate the computational performance for each GPU. The green marker represents the measured performance (Arithmetic Intensity and GFLOPS). The blue region indicates the memory-bound performance, while the red region highlights the compute-bound performance.
RTX 4080 Roofline Plot
A100 Roofline Plot
Optimization Strategies
To achieve maximum performance, the kernel employs the following optimizations:
Fused Multiply-Add (FMA)
Improves efficiency by reducing separate multiply and add instructions.
Early Exit for Diverging Points
Reduces unnecessary computations by terminating iterations as soon as a point diverges.
Loop Unrolling
Optimizes control flow using @unroll 128, reducing overhead.
Memory Coalescing
Ensures efficient global memory access patterns, reducing memory latency.
High-Occupancy Thread Blocks
Maximizes the number of active threads per Streaming Multiprocessor (SM) for full utilization of GPU cores.
Mandelbrot Image Visualization
The Mandelbrot set is rendered using a red intensity gradient, which smoothly transitions from black (converging points) to increasing shades of red (diverging points) as the iteration count approaches the maximum value.

Dependencies
To run this project, install the following Julia packages:
using Pkg
Pkg.add("CUDA")
Pkg.add("Colors")
Pkg.add("Images")
Pkg.add("FileIO")
Pkg.add("IndirectArrays")
Pkg.add("KernelAbstractions")